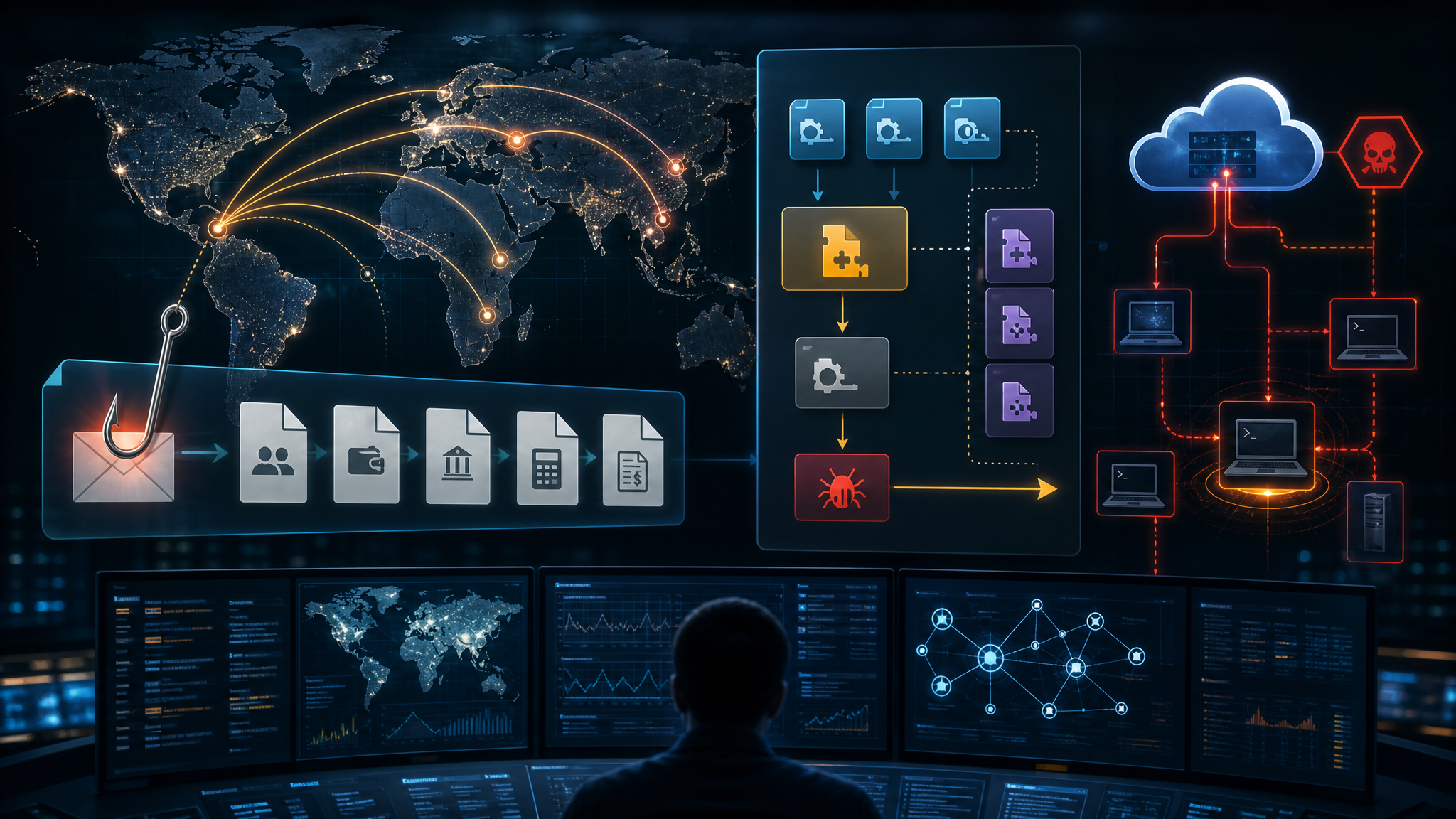
A groundbreaking research paper by Bruce Schneier and collaborators introduces the concept of “promptware”—a distinct class of malware targeting large language models (LLMs). Moving beyond the myopic focus on prompt injection, the researchers propose a structured seven-step kill chain that mirrors traditional cyberattack frameworks like those used to analyze Stuxnet and NotPetya.
The Seven-Stage Promptware Kill Chain
1. Initial Access: Malicious payloads enter AI systems through direct prompts or, more dangerously, indirect prompt injection via web pages, emails, or documents the LLM retrieves. With multimodal models, attacks can now hide in images or audio files.
2. Privilege Escalation (Jailbreaking): Attackers circumvent safety guardrails through techniques analogous to social engineering—convincing models to adopt personas that ignore rules or using adversarial suffixes. This unlocks full model capabilities for malicious use.
3. Reconnaissance: Unlike traditional malware, promptware reconnaissance occurs after initial access. The attack manipulates the LLM to reveal information about connected services and capabilities, turning the model’s reasoning against itself.
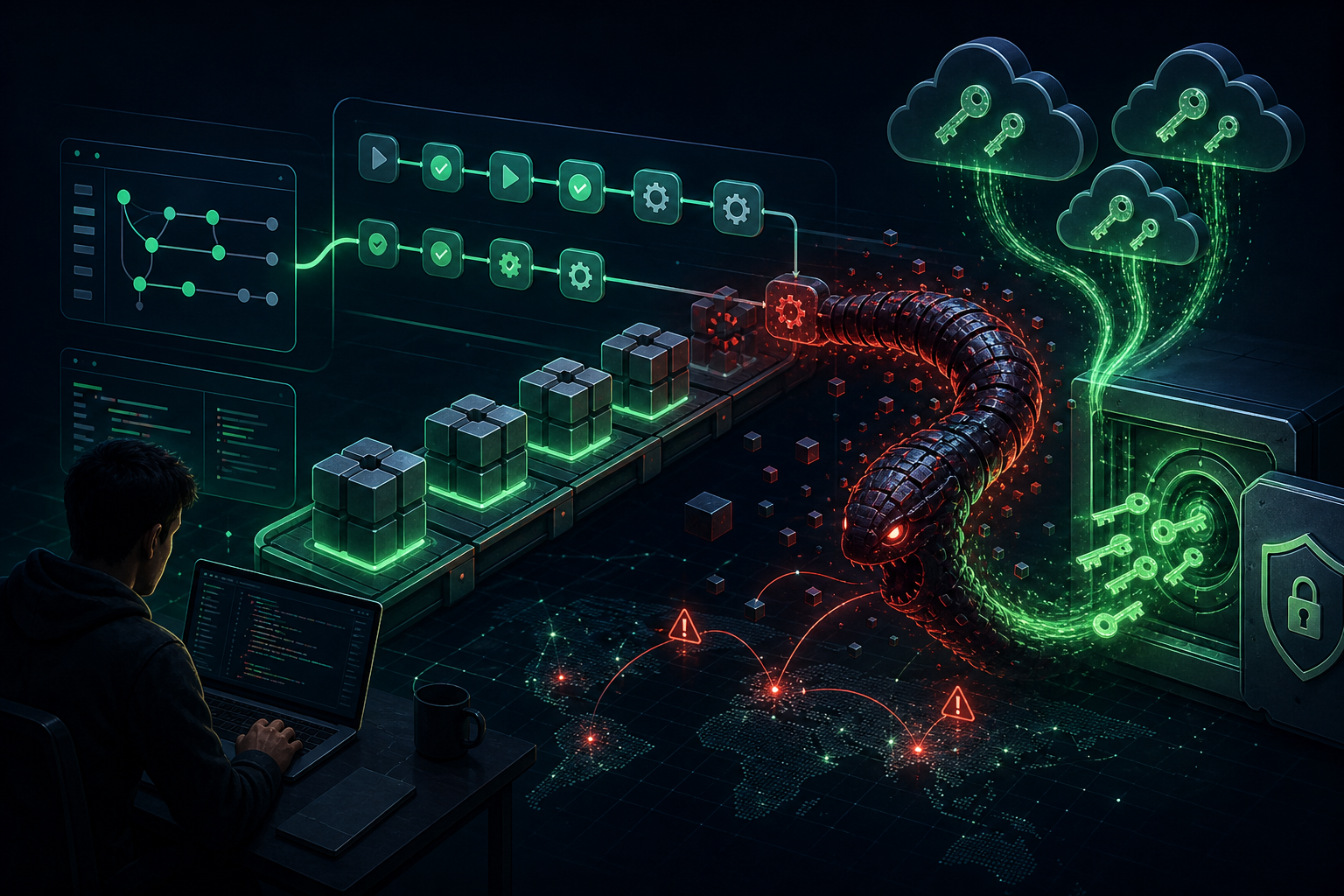
4. Persistence: Promptware embeds itself into AI agents’ long-term memory or poisons retrieval databases, ensuring re-execution every time the AI accesses compromised data.
5. Command and Control (C2): Leveraging dynamic fetching capabilities, promptware transforms from a static threat into a controllable trojan with evolving behavior.
6. Lateral Movement: Self-replicating attacks can spread through connected systems. An infected email assistant might forward malicious payloads to all contacts, creating viral propagation through enterprise AI ecosystems.
7. Actions on Objective: Final goals include data exfiltration, financial fraud, and arbitrary code execution—with documented cases of AI agents transferring cryptocurrency to attacker wallets.
Real-World Kill Chain Demonstrations
The “Invitation Is All You Need” research demonstrated the full chain: attackers embedded malicious prompts in Google Calendar invitations, achieved persistence in workspace memory, executed lateral movement via Zoom, and covertly livestreamed victims’ video feeds.
Similarly, the “Here Comes the AI Worm” research showed self-replicating attacks spreading through email assistants, exfiltrating sensitive data while infecting new victims with sublinear propagation.
Why This Matters
The fundamental vulnerability lies in LLM architecture itself: unlike traditional computing systems, LLMs process all input—system commands, user emails, retrieved documents—as a single undifferentiated token sequence with no boundary between trusted instructions and untrusted data.
Prompt injection isn’t fixable in current LLM technology. Instead, the researchers advocate for defense-in-depth strategies that assume initial access will occur and focus on breaking the chain at subsequent steps.
Source: Schneier on Security | Lawfare